
Attention-based End-to-End Speech-to-Text Deep Neural Network
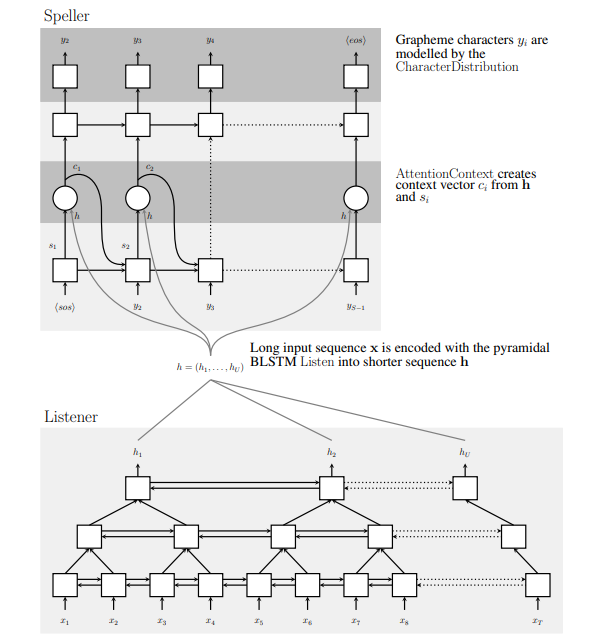
- Implemented character-based encoder, decoder, and attention modules for non order synchronous seq to seq translation based on “Listen, Attend and Spell” Chan et al.
- Implemented pyramidal bi-LSTM layers as part of the encoder module.
- Implemented random search over the output of the decoder to select the most probable sequence.